
Background
In the past year, Branch has continued to experiment with ways that generative AI can be used in the practice of making loans. We call this Generative Credit.
A few of our experiments have really paid off and we think lenders and borrowers alike will really benefit from these new technologies. For Branch, we have seen some amazing results. For instance, in the last 12 months:
The Branch loan book has doubled:
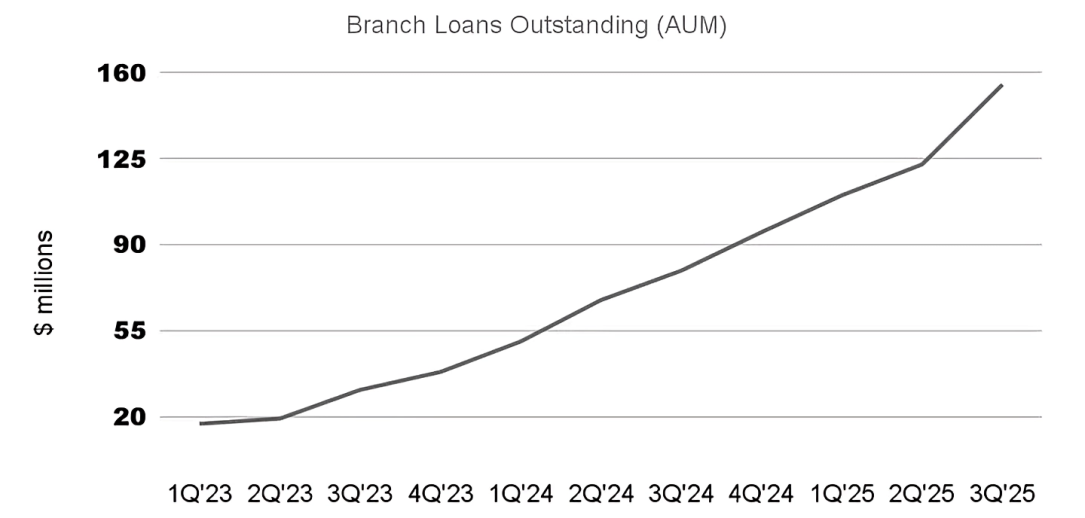
At the same time, our default rate has reduced by about 40%:
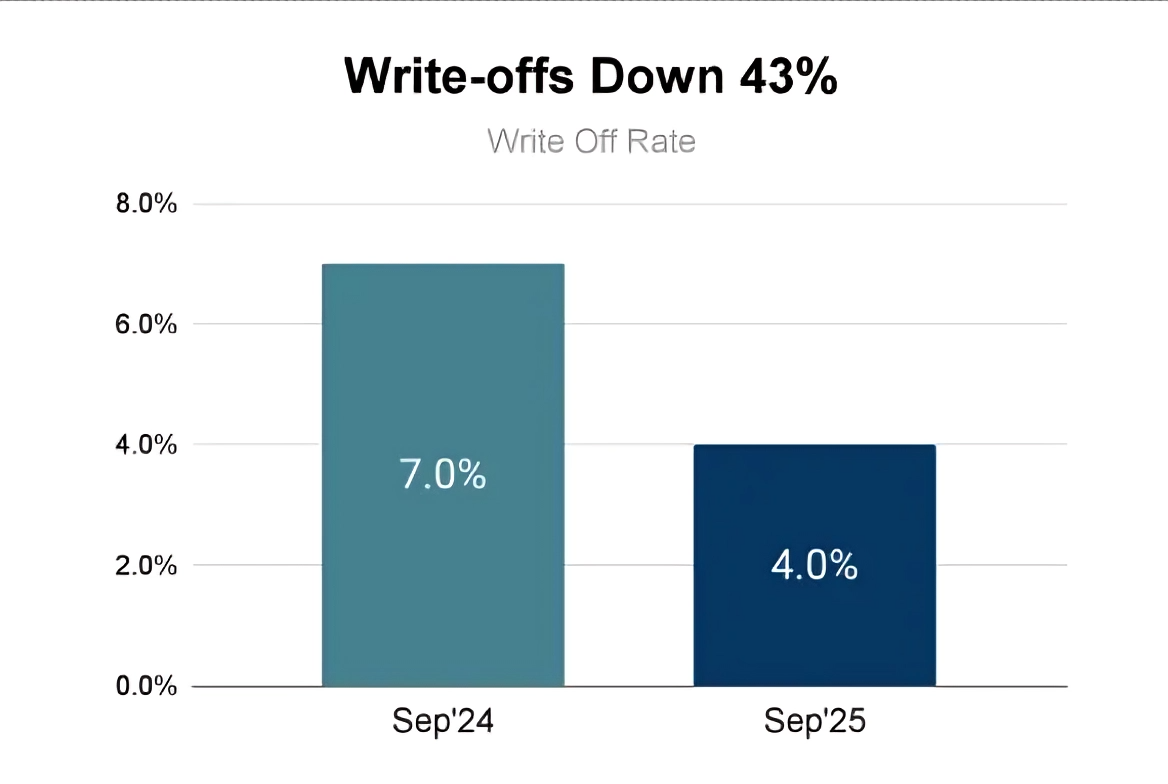
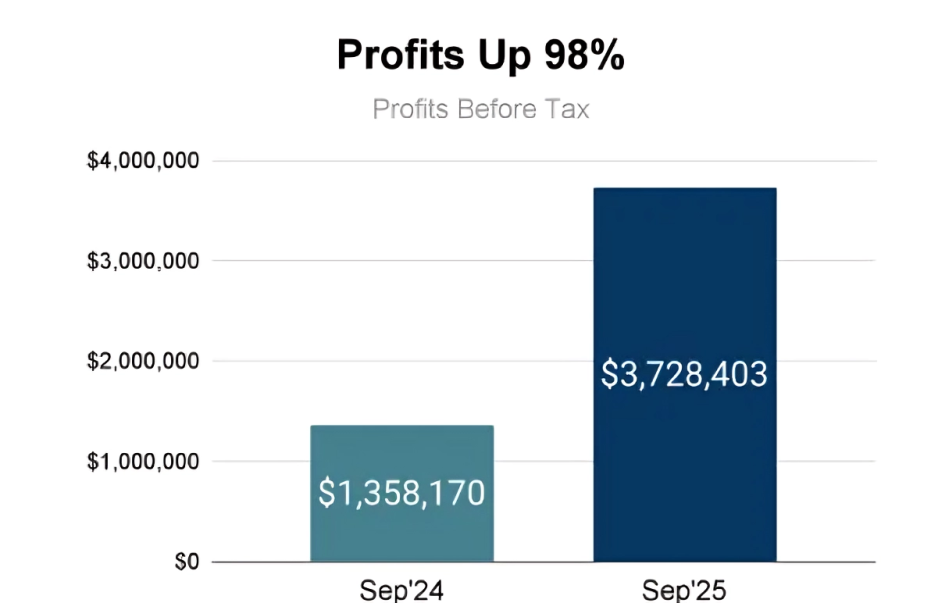
We now make about 40,000 loans per day on average while making an annualized profit (before tax) of about $40M globally. To be honest, this amount of profit is way more than projected. We intend to pour this back into the portfolio by lowering prices steadily every month.
One of the key enablers of this progress recently has been the use of Agents. In particular, score drift agents.
Let us explain.
Why We Built This
Every model starts out shiny and accurate, until the world changes. User behavior evolves, data processes drift, regulations update, and one morning your credit risk model starts giving slightly different scores.
We’ve all been there.
When model scores shift, the effects ripple through the business. A small change in score distributions can quietly alter approval rates, risk mix, and even customer experience. One week, you might be approving slightly fewer good borrowers; another, you might be taking on more risk than intended. These shifts don’t usually announce themselves—they show up as slow, invisible drifts that only become obvious when KPIs move.
That’s why catching and understanding score drift early matters so much.
At Branch, we already have automated monitoring pipelines that run daily checks for data drifts and score drifts. They work great for the usual stuff like “is this week different from last week?” But when we want to compare any two arbitrary periods or specific user segments on the fly, it turns into a mini project. Someone has to write queries, set up joins, and rebuild plots.
So we built a score drift agent: an AI sidekick that lets us run root-cause analyses conversationally. Instead of diving into dashboards and notebooks, we can just ask, “Why do user scores from March look different from June?” and the agent does the digging.
Our Take on AI Agents
Everyone seems to have their own idea of what an AI agent is. Some picture it as a digital teammate. Something that can reason about goals, plan a few steps ahead, and take actions using tools.
That’s actually a pretty good mental model.
At a high level, an AI agent is any system that can reason, act, and improve. It looks at a goal (“find out why scores dropped”), figures out what to do next (“compare two groups of users”), uses the right tools (“run a model, plot a distribution, fetch SHAP values”), and stops once it has a good answer.
Under the hood, though, an agent is built from just a few core parts:
- Reasoning model: usually a large language model that interprets context and decides which step to take next.
- Tools: the actions it can perform, from querying data to running analysis code.
- Instruction: what defines its task, boundaries, and when it should stop.
When you connect several agents that can pass tasks between each other you get a multi-agent system, a small ecosystem where each agent has a clear purpose and collaborates to solve complex problems.
Our score drift agent is one such member of that ecosystem. Its reasoning model helps it explore “why” questions, and one of its key tools is a simple but powerful method for Root Cause Analysis (RCA): comparing groups to uncover what’s driving the difference between them.
Root Cause Analysis: The Comparison Trick
The image below shows the tools our score drift agent can use. For any good RCA agent, it all starts with having the right set of comparison tools.
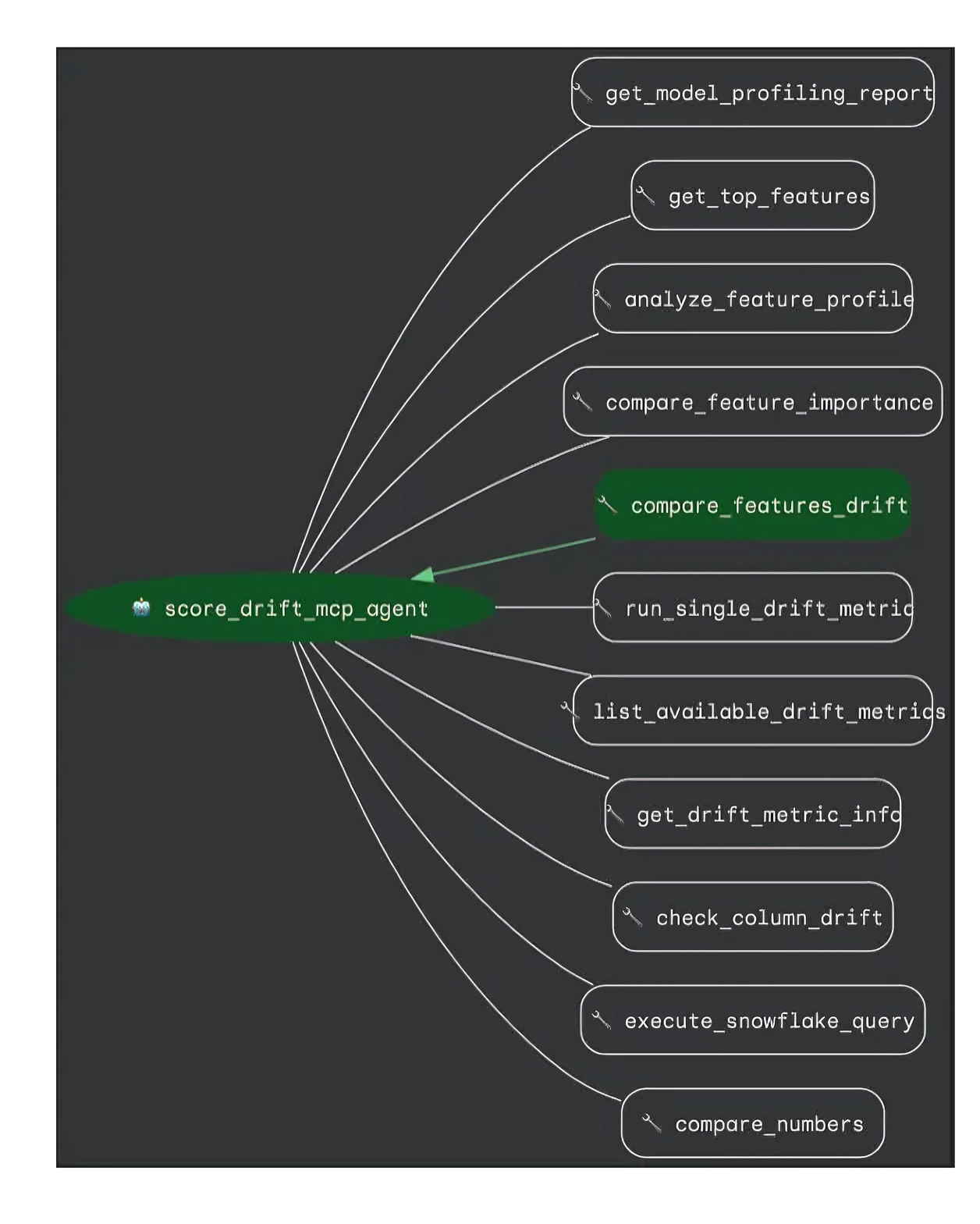
Here’s a quick methodology for a comparison tool like compare_features_drift:
- Take two groups, for example, users from Period A and Period B. For each user, you have a bunch of attributes.
- Train a model to predict whether a user belongs to A or B based on these attributes.
- The attributes that are most predictive are the ones driving the difference.
That’s it. A simple yet powerful way to see both single-variable and interaction effects.
So when our agent wants to explain a drift, it builds this comparison behind the scenes. The most discriminative features inform our first set of hypotheses to explore.
From RCA to Score Drift
Now, let’s apply this idea to credit scoring.
A score drift happens when model outputs change meaningfully between time periods or cohorts. Maybe everyone’s scores are slightly lower this month, or a particular segment suddenly looks riskier.
To figure out why, the agent compares two groups of users, say June vs. July or Android vs. iOS, and identifies what changed.
There are two ways to do this:
- Feature-based drift: Compare the model’s input features directly. This shows how user behavior or data has shifted even if it doesn’t affect the score yet.
- SHAP-based drift: Compare SHAP values (feature contributions to model predictions). This highlights only those data changes that actually drive score differences.
Using SHAP values makes the analysis model-aware. It filters out noise and focuses on the changes that truly matter.
A Real-World Example
A few months ago, a change at one of our credit bureau partners subtly changed how they formatted the data we receive. Everything kept working—the files arrived, fields looked familiar—but a few small differences in the data started creeping in.
Over a few weeks, this caused a slow, barely noticeable shift in some bureau-related features, which eventually nudged our model scores. Our daily drift alerts didn’t go off since they were tuned to catch sudden spikes, not gentle slopes. Initially we updated decision thresholds and hoped that it would stabilize but the scores kept going down.
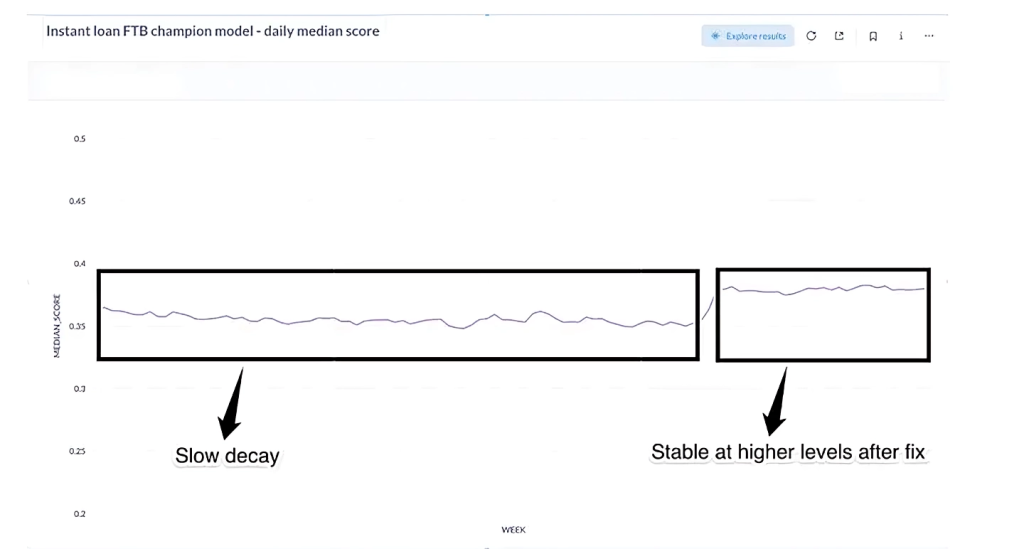
Then, during a chat with the score drift agent, we asked it to compare two time periods. The affected credit bureau features were able to predict which example belonged to which cohort with near perfect accuracy, pointing to a clear issue in these features. Then we started looking into the raw data and identified the subtle change. After updating the mapping to include the new format the score distribution recovered to its expected range.
So we traced the root cause back to the data format change. Once we fixed our parser, the drift disappeared. What made this powerful was how we discovered it: not through a dashboard alert, but through an ad hoc, conversational investigation that felt almost like pair-debugging with a data scientist who never sleeps.
What We Learned
- Make modular agents. Build them with small, reusable tools and a clear intent.
- Root-cause analysis is universal. The same method can diagnose score drift, approval-rate drift, or even repayment-pattern drift.
- SHAP adds signal, removes noise. Making RCA model-aware ensures we’re chasing changes that actually affect decisions.
- Human + agent > either alone. As we work on making the agents more powerful and autonomous, the human-in-the-loop aspect remains important to get the job done.
The Road Ahead
The score drift agent is part of a larger initiative we call Generative Credit, a collection of AI agents helping us understand, monitor, and evolve our credit systems faster than ever.
Next, we’re exploring a multi-agent setup: one agent that detects drift, another that runs RCA, and a third that suggests possible fixes or retraining strategies.
Comments